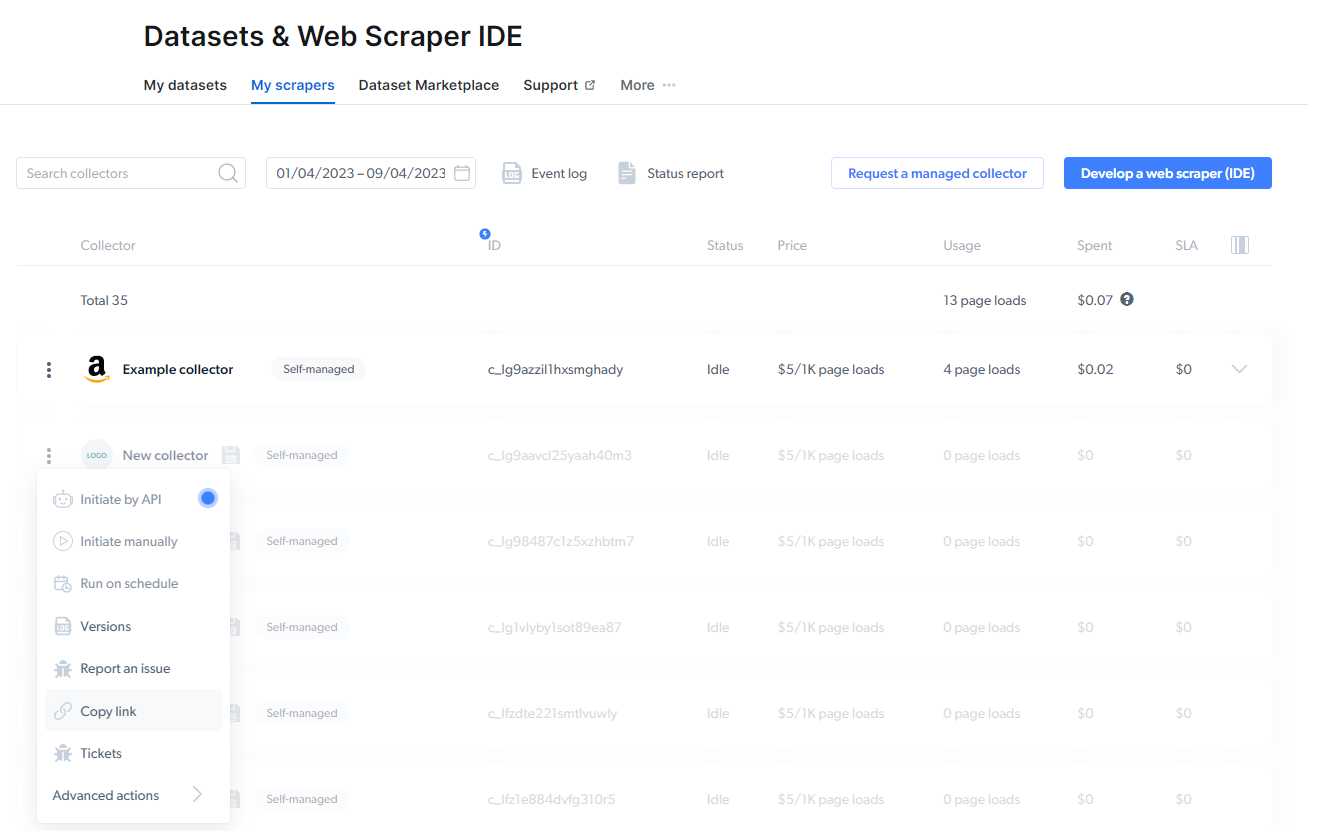
启动抓取器
要开始收集数据,请从以下三个选项中选择一个:- 通过API启动
- 手动启动
- 安排抓取器
您可以通过API开始数据收集,无需访问Bright Data控制面板:开始使用API文档在启动API请求之前,请创建API令牌。 要创建API令牌,请转到:
控制面板侧边菜单设置 > 账户设置 > API令牌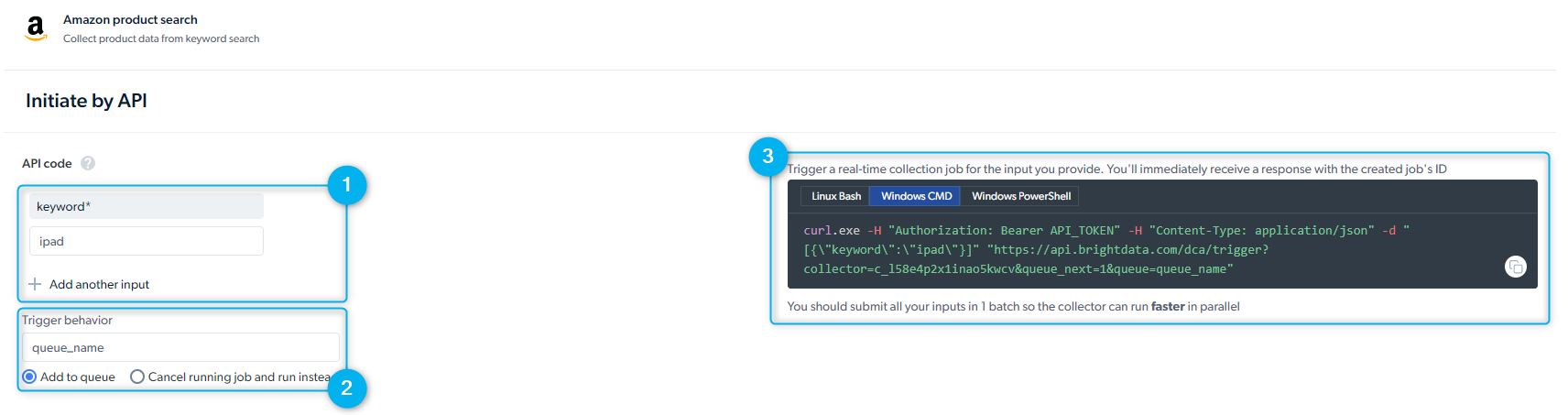
- 手动设置输入 - 手动输入或通过API请求输入数据
- 触发行为 - 您可以添加多个并行请求,这些请求将根据定义的顺序激活。您可以将另一个作业添加到队列中,并同时运行两个以上的作业。
- API请求预览 - Bright Data为您提供REST API调用,用于启动抓取器。请选择“Linux Bash”查看器以查看CURL命令。发送请求后,您就会立即收到作业ID。
如果交付首选项设置为API下载,则必须具有调用API才能接收数据
交付选项
您可以为数据集设置交付首选项。要进行此设置,只需点击“我的抓取器”选项卡中的抓取器行,然后点击“交付首选项”即可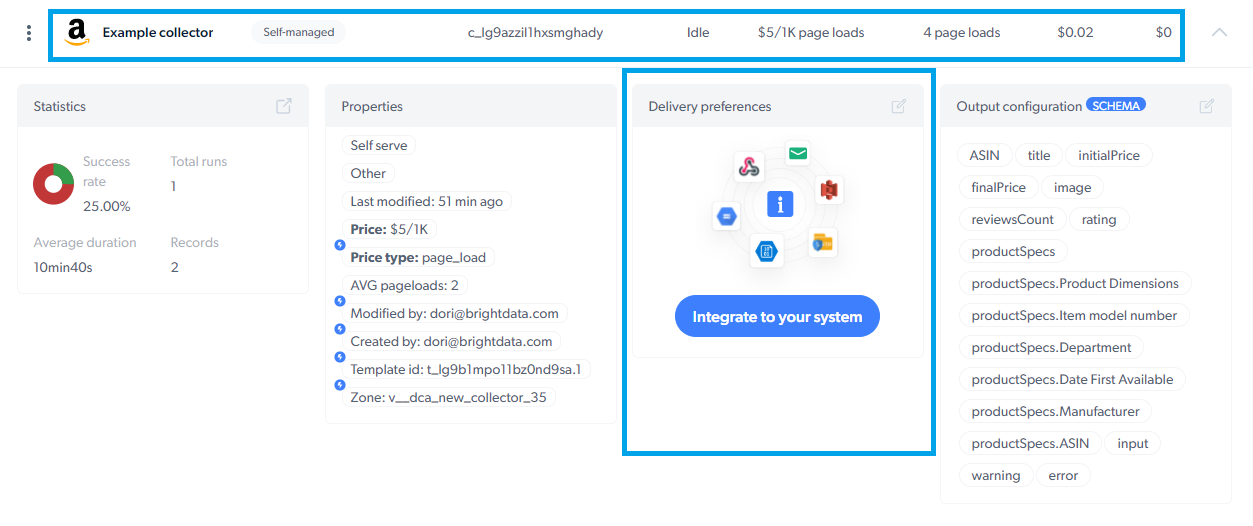
选择何时获取数据
选择何时获取数据
- 批量:管理大量数据的有效方式
- 分批:数据准备好后,立即分小批量交付
- 实时:快速响应一个请求的理想方式
- 跳过重试:发生错误时不重试。 可以加快收集速度
选择文件格式
选择文件格式
- JSON
- NDJSON
- CSV
- XLSX
选择如何接收数据
选择如何接收数据
- 电子邮件
- API下载
- Webhook
- 云存储提供商:Amazon S3、Google Cloud Storage、Azure
- SFTP/FTP
如果设置为电子邮件或API下载,则媒体文件无法交付
选择结果格式
选择结果格式
- 结果和错误分别存放在不同文件中
- 结果和错误一起存放在一个文件中
- 仅包含成功结果
- 仅包含错误
定义通知
定义通知
- 在收集完成时发出通知
- 提供成功率的通知
- 在发生错误时发出通知
输出架构
架构定义了数据点结构以及数据的组织方式。 您可以更改架构结构和修改数据点以满足您的需求,包括重新排序、设置默认值,以及将其他数据添加到输出配置中。 要添加新的字段名称,请进入高级设置并编辑代码。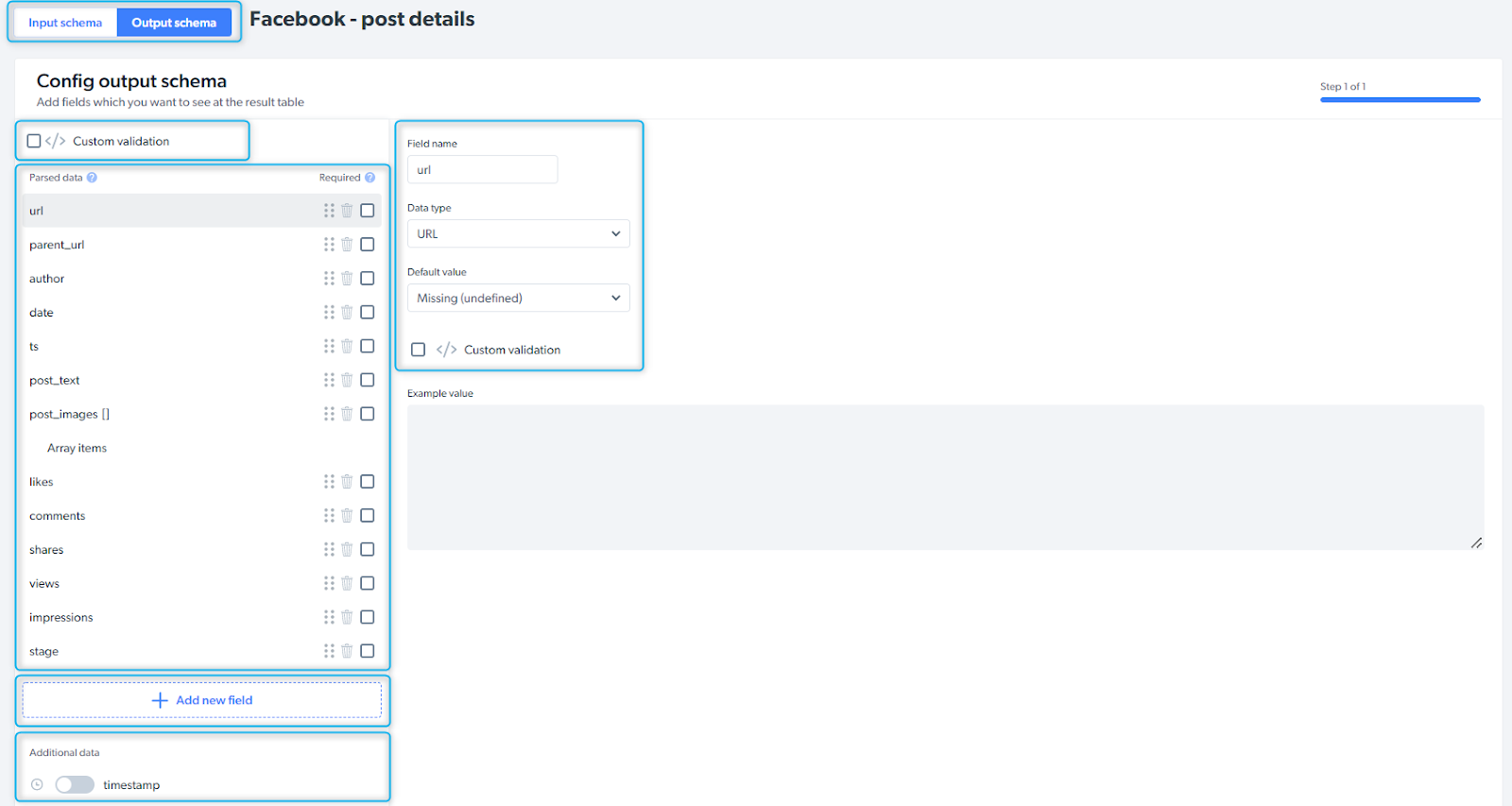
| 输入/输出架构 | 选择要配置的选项卡 |
| 自定义验证 | 验证架构 |
| 已解析的数据 | 抓取器收集的数据点 |
| 添加新字段 | 如果您需要其他数据点,可以添加字段,并定义字段名称和类型 |
| 附加数据 | 您可以将附加信息(时间戳、截图等)添加到架构中 |