Scraping methods
Synchronous scraping (/scrape)
Synchronous scraping allows you to initiate a scrape and receive results in a single request, ideal for real-time quick data retrieval.
Key features of synchronous scraping:
- Real-time results in the same request
- Perfect for single URL and quick extractions
- Simplified error handling
- 1-minute timeout (automatically switches to async if exceeded)
Asynchronous scraping (/trigger)
Asynchronous scraping initiates a job that runs in the background, allowing you to handle larger and more complex scraping tasks in batch mode. Batch mode allows up to 100 concurrent requests, and each batch can process up to 1GB of inputs file size, making it ideal for high-volume data collection projects.
Discovery tasks (finding related products, scraping multiple pages) require the asynchronous scraping (/trigger) due to their need to navigate and extract data across multiple web pages.
Key features of asynchronous scraping:
- Handles multiple URLs in batch processing (up to 1GB of inputs file size)
- No timeout limitations for long-running jobs
- Progress monitoring via status checks
- Ideal for large datasets
- Required for “discovery” tasks that need to crawl multiple pages or perform complex data extraction
Choosing between synchronous and asynchronous scraping
| Use case | Recommended method |
|---|---|
| Quick data checks | Synchronous (/scrape) |
| Single page extraction | Synchronous (/scrape) |
| Multiple pages or URLs (For batch processing up to 5K URLs on average) | Asynchronous (/trigger) |
| Complex scraping patterns | Asynchronous (/trigger) |
| Large datasets | Asynchronous (/trigger) |
How To Collect?
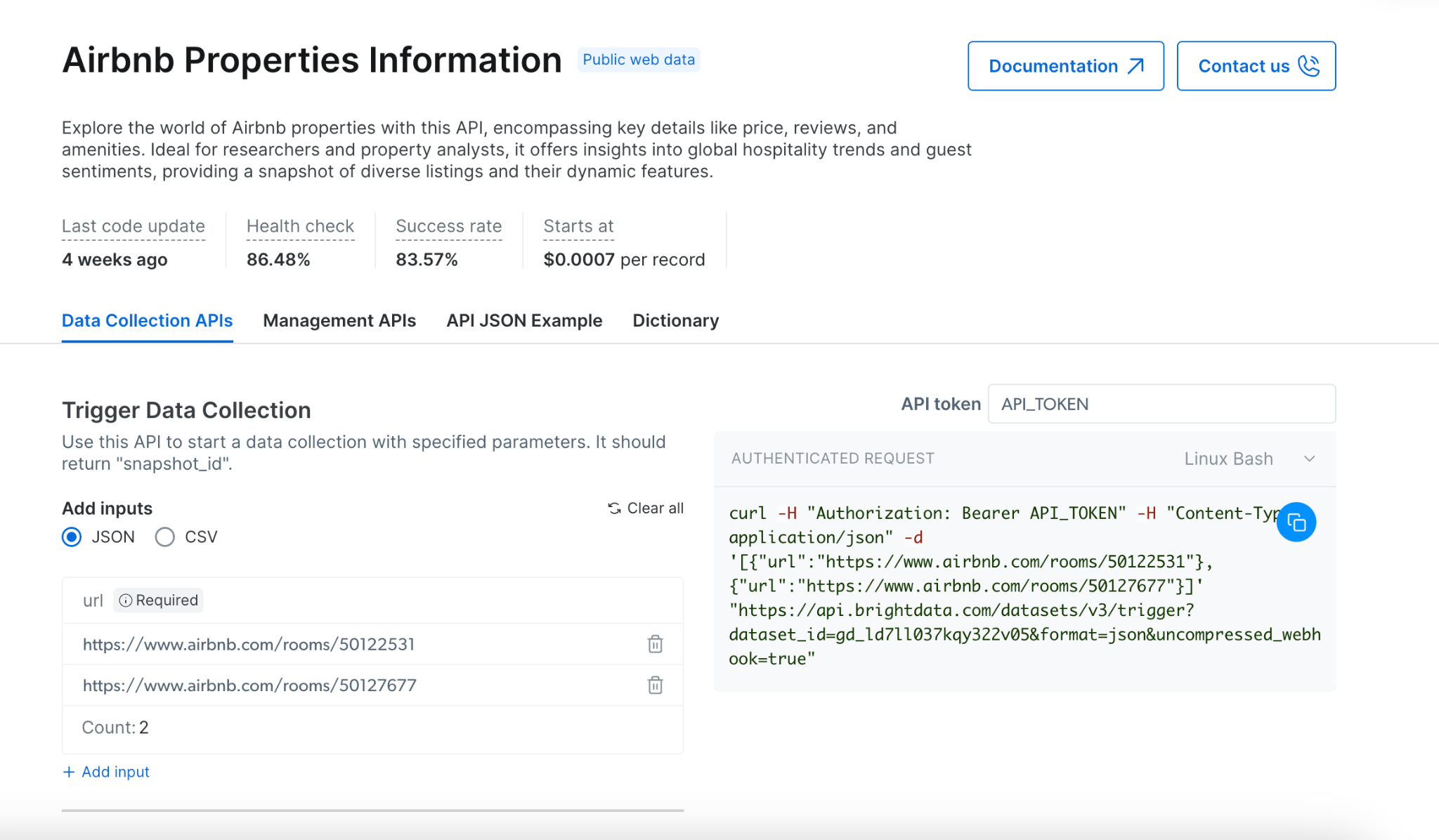
Trigger a Collection (Demo)
- Choose your target website from our API offerings
- Select the appropriate scraper for your needs
- Decide between synchronous or asynchronous scraping based on your requirements:
- Use synchronous (
/scrape) for immediate results and simple extractions - Use asynchronous (
/trigger) for complex scraping, multiple URLs, or large datasets
- Use synchronous (
- Provide your input URLs via JSON or CSV
- Enable error reporting to track any issues
- Select your preferred delivery method
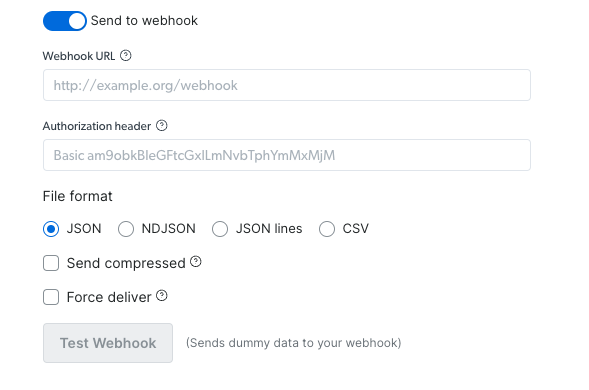
Via Webhook:
- Set your webhook URL and Authorization header if needed
- Select your preferred file format (JSON, NDJSON, JSON lines, CSV)
- Choose whether to send it compressed or not
- Test webhook to validate that the operation runs successfully (using sample data)
- Copy the code and run it.
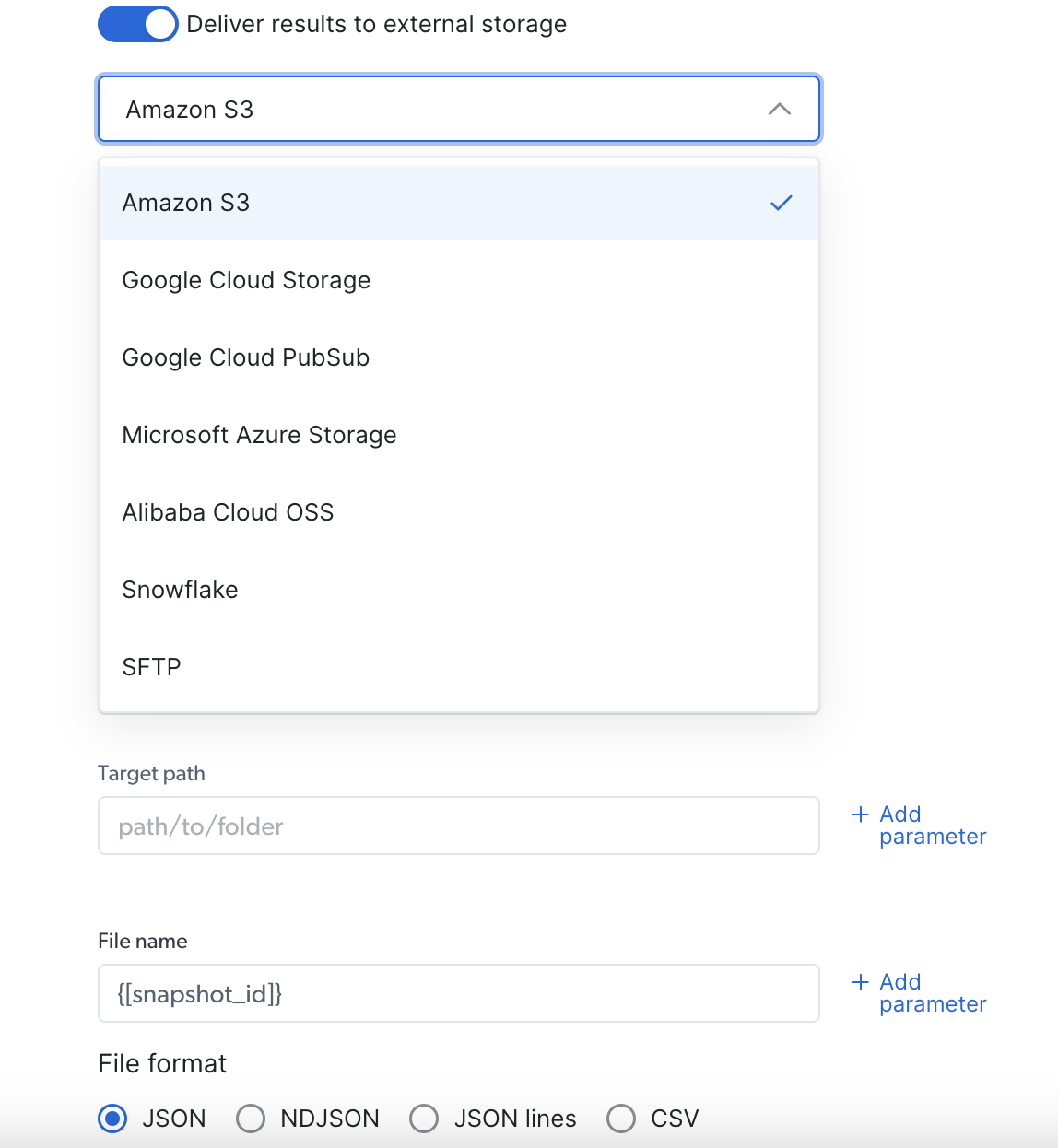
Via Deliver to external storage:
- Select your preferred delivery location (S3, Google Cloud, Snowflake, or any other available option)
- Fill out the needed credentials according to your pick
- Select your preferred file format (JSON, NDJSON, JSON lines, CSV)
- Copy the code and run it.
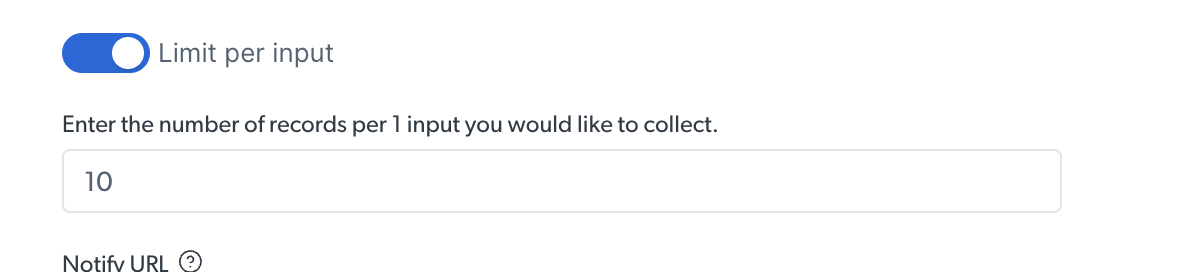
Limit records
While running a discovery API, you can set a limit of the number of results per input provided
Management APIs
Additional actions you can do using our different API endpoints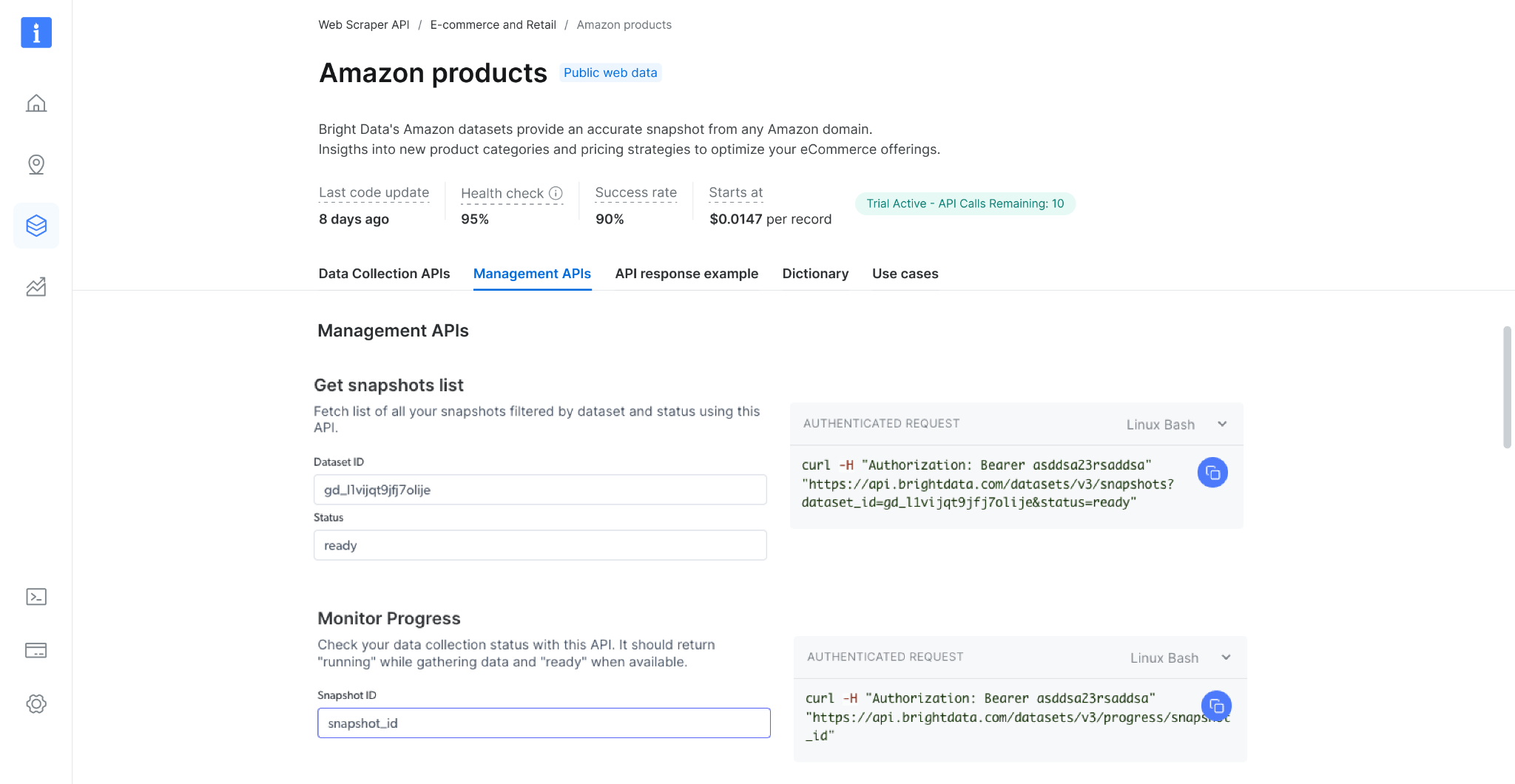
Get snapshot list
Check your snapshot history with this API. It returns a list of all available snapshots, including the snapshot ID, creation date, and status. (link to endpoint playground)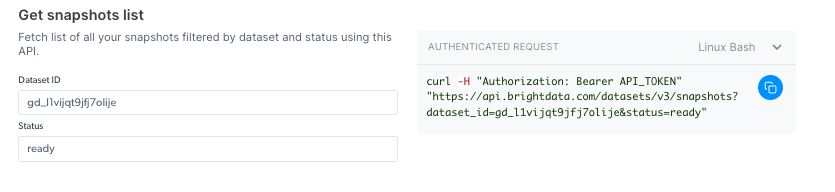
Monitor Progress
Check your data collection status with this API. It should return “collecting” while gathering data, “digesting” when processing, and “ready” when available. (link to endpoint playground)
Cancel snapshot
Cancel a running collection, stop your data collection before finishing with this API. It should return “ok” while managing to stop the collection. (link to endpoint playground)Monitor Delivery
Check your delivery status with this API. It should return “done” while the delivery was completed, “canceled” when the delivery was canceled, and “Failed” when the delivery was not completed. (link to endpoint playground)System limitations
File size
| Input | up to 1GB |
| Webhook delivery | up to 1GB |
| API Download | up to 5GB (for bigger files use API delivery) |
| Delivery API | unlimited |
Rate Limits & Concurrent Requests
To ensure stable performance and fair usage, the Web Scraper API enforces rate limits based on the type of request: single input or batch input. Exceeding these limits will result in a 429 error response.What is the Rate Limit?
The Web Scraper API supports the following maximum number of concurrent requests:| Method | Rate-limit |
|---|---|
| Up to 20 inputs per request | up to 1500 concurrent requests |
| Over 20 inputs per request | up to 100 concurrent requests |
429 Client Error: Too Many Requests for URLThis error indicates that your request rate has surpassed the allowed threshold.
How to Avoid Hitting Rate Limits
To reduce the number of concurrent requests and stay within the rate limits:- Use the batch input method whenever possible.
- A single batch request can include up to 1GB of input data (file size).
- By combining multiple inputs into one batch request, you can minimize the total number of requests sent concurrently.
Best Practices for Managing API Rate Limits
- Monitor your request volume and adjust your concurrency accordingly.
- Use batch requests to group multiple scraping tasks into fewer API calls.
- Contact our support team if you need help optimizing your requests.